You can create multiple read replicas for a given source DB Instance and distribute your application's read traffic amongst them. It goes without saying that many SQL Server queries are easier to formulate with words than with T-SQL. The more you master the SQL Server language, the easier it could be for you to express queries directly in T-SQL. However, for the vast majority of developers working on data-access components, finding a T-SQL counterpart for the following query could be difficult.

Let's consider a query that returns for each customer the total number of orders he placed in given timeframe. The query clearly involves a join between customers and orders. Listing 5 shows how you'd write it using a LINQ to SQL object model and the LINQ query language. The SQL standard defines SQL/JRT extensions to support Java code in SQL databases. PostgreSQL lets users write functions in a wide variety of languages—including Perl, Python, Tcl, JavaScript (PL/V8) and C. The GROUP BY clause groups together rows in a table with non-distinct values for the expression in the GROUP BY clause.

For multiple rows in the source table with non-distinct values for expression, theGROUP BY clause produces a single combined row. GROUP BY is commonly used when aggregate functions are present in the SELECT list, or to eliminate redundancy in the output. By setting the LoadOptions property, you specify a static fetch plan that tells the runtime to load all customer information at the same time order information is loaded. Based on this, the LINQ to SQL engine can optimize the query and retrieve all data in a single statement.

Listing 4 shows the SQL Server Profiler detail information for the exec sp_executesql query after the code modification. The query now includes a LEFT OUTER JOIN that loads orders and related customers in a single step. You may think that after running the first query to grab all matching records in the Orders table, you're fine and can work safely and effectively with any selected object.
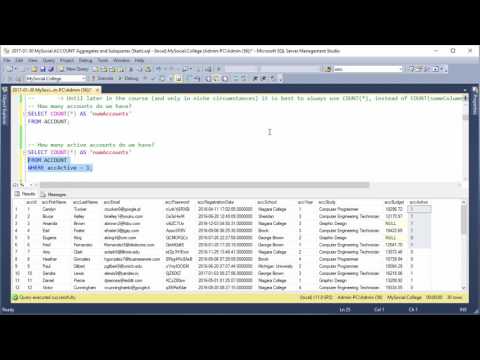
How Do You Write A Group By Query In SQL As Figure 2 shows, many additional queries actually hit the SQL Server database. Let's expand on one of them, the exec sp_executesql statement, in Listing 3. All additional queries are similar to the preceding query, and all they do is retrieve information about the customer who placed the order being processed in the foreach loop in Listing 2. Pluck can be used to query single or multiple columns from the underlying table of a model.

It accepts a list of column names as an argument and returns an array of values of the specified columns with the corresponding data type. However, there may be use cases where advanced users wish to complete Data Definition Language SQL statements against a read replica. Examples might include adding a database index to a read replica that is used for business reporting without adding the same index to the corresponding source DB instance. Union expression returns only unique rows as if each query returned distinct results. If you need to combine multiple result sets without removing duplicate rows consider using union_all/2.

Intersect expression returns only unique rows as if each query returned distinct results. If you need to take the intersection of multiple result sets without removing duplicate rows consider using intersect_all/2. Except expression returns only unique rows as if each query returned distinct results.

If you need to take the difference of multiple result sets without removing duplicate rows consider using except_all/2. The LINQ query engine is extensible enough to support any collection of objects that exposes a made-to-measure interface—the IQueryable interface. LINQ to SQL, in particular, wraps the content of a SQL Server database and makes it queryable through the LINQ syntax. Even though it's the opposite of growth, churn is an important metric as well.

Many companies keep track of their churn rates, especially if their business model is subscription-based. This way, they can track the number of lost subscriptions or accounts, and predict the reasons that caused it. An experienced data scientist will be expected to know which functions, statements, and clauses to use to calculate churn rates. DQL statements are used for performing queries on the data within schema objects.

The purpose of the DQL Command is to get some schema relation based on the query passed to it. We can define DQL as follows it is a component of SQL statement that allows getting data from the database and imposing order upon it. This command allows getting the data out of the database to perform operations with it. When a SELECT is fired against a table or tables the result is compiled into a further temporary table, which is displayed or perhaps received by the program i.e. a front-end.
LINQ to SQL doesn't work with databases other than SQL Server. So, unlike ADO.NET or industry-standard object-relational mapping tools, you can't use LINQ to SQL to work with, say, Oracle databases. LINQ to SQL doesn't attempt to push an alternate route and doesn't aim to replace T-SQL; it simply offers a higher-level set of query tools for developers to leverage.

LINQ to SQL is essentially a more modern tool to generate T-SQL dynamically based on the current configuration of some business-specific objects. T-SQL operates on a set of tables, whereas LINQ to SQL operates on an object model created after the original set of tables. It is particularly useful in handling structured data, i.e. data incorporating relations among entities and variables. SQL offers two main advantages over older read–write APIs such as ISAM or VSAM.

Firstly, it introduced the concept of accessing many records with one single command. Secondly, it eliminates the need to specify how to reach a record, e.g. with or without an index. In this article, I am giving some examples of SQL queries which is frequently asked when you go for a programming interview, having one or two year experience in this field.
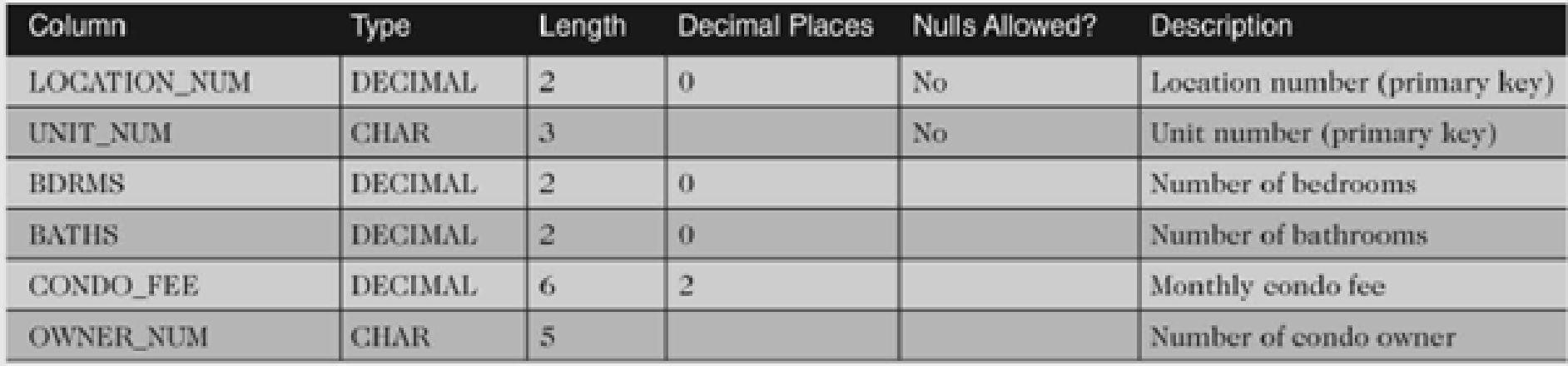
We should follow certain best practices while designing objects in SQL Server. For example, a table should have primary keys, identity columns, clustered and non-clustered indexes, constraints to ensure data integrity and performance. Even we follow the best practices, and we might face issues such as duplicate rows. We might also get these data in intermediate tables in data import, and we want to remove duplicate rows before actually inserting them in the production tables. You may use the query builder's where method to add "where" clauses to the query.

The most basic call to the where method requires three arguments. The second argument is an operator, which can be any of the database's supported operators. The third argument is the value to compare against the column's value. Data scientists will also have to prove their skills in formatting the data and displaying it as percentages or in any other form. In general, to solve the practical questions where you have to calculate month-over-month growth, you must use the combination of multiple skill sets. Some of the required concepts will be advanced (window functions, date-time manipulation), while others will be basic .
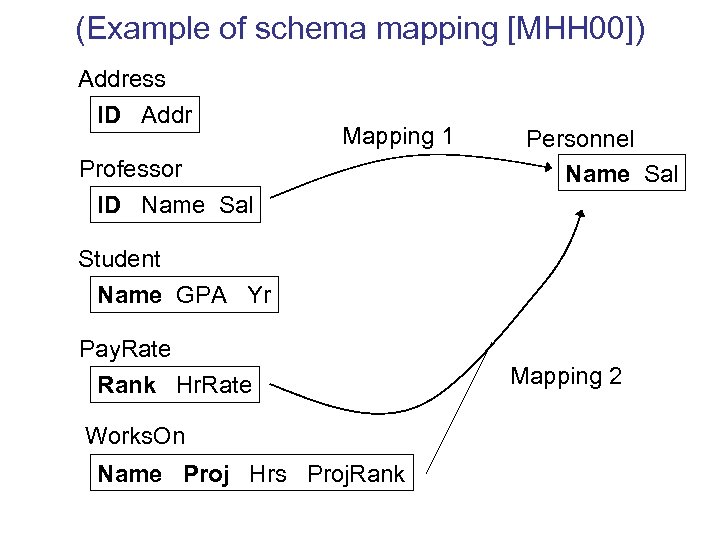
You should, in general, have a thorough experience and mastery of using joins in combination with other statements to achieve the desired results. For instance, you should know how to use the WHERE clause to utilize Cross Join as if it was an Inner Join. You will also be expected to know how to use joins to produce new tables without putting too much pressure on the server. Or how to use outer joins to identify and fill in the missing values when querying the database.

Or the inner workings of outer joins, such as the fact that rearranging their order can change the output. You also benefit from enhanced database availability when running your DB instance as a Multi-AZ deployment. If an Availability Zone failure or DB instance failure occurs, your availability impact is limited to the time automatic failover takes to complete. The availability benefits of Multi-AZ also extend to planned maintenance. For example, with automated backups, I/O activity is no longer suspended on your primary during your preferred backup window, since backups are taken from the standby.
In the case of patching or DB instance class scaling, these operations occur first on the standby, prior to automatic failover. As a result, your availability impact is limited to the time required for automatic failover to complete. By default, the upgrade will be applied or during your next maintenance window. You can also choose to upgrade immediately by selecting the Apply Immediately option in the console API. When you have more complex queries that involve JOIN and GROUPBY operations, you can project on joined fields as well and apply functions to groups of data. The syntax of the select new keyword is flexible enough to accommodate an explicit property naming.

In the JOIN example shown earlier, you explicitly set the name of the column that reports the total number of orders for a customer to OrderCount. The completed data context class incorporates references to collections that represent all selected tables. The data context source file also includes the definition of a class that represents an individual row on each selected table. In other words, if you select the Customers and Orders tables from the Northwind database, you'll have in the data context class properties, which the C# code sample in Listing 1 shows. In this method, we use the SQL GROUP BY clause to identify the duplicate rows.

The Group By clause groups data as per the defined columns and we can use the COUNT function to check the occurrence of a row. Suppose your SQL table contains duplicate rows and you want to remove those duplicate rows. It is a best practice as well to use the relevant keys, constrains to eliminate the possibility of duplicate rows however if we have duplicate rows already in the table. We need to follow specific methods to clean up duplicate data. This article explores the different methods to remove duplicate data from the SQL table. The ORDER BY clause specifies a column or expression as the sort criterion for the result set.

If an ORDER BY clause is not present, the order of the results of a query is not defined. The default sort direction is ASC, which sorts the results in ascending order of expression values. Column aliases from a FROM clause or SELECT list are allowed.
If a query contains aliases in the SELECT clause, those aliases override names in the corresponding FROM clause. This query returns every city document where the regions field is an array that contains west_coast. If the array has multiple instances of the value you query on, the document is included in the results only once.

Transparency of each pixel, specified as the comma-separated pair consisting of 'Alpha' and a matrix of values in the range . The row and column dimensions of the Alpha matrix must be the same as those of the image data array. You can specify Alpha only for grayscale (m-by-n) and truecolor (m-by-n-by-3) image data. Imwrite writes each row of input as a comment in the JPEG 2000 file.

Imwrite writes each row of input as a comment in the JPEG file. The SQL WHERE clause is used to specify a condition while fetching the data from a single table or by joining with multiple tables. If the given condition is satisfied, then only it returns a specific value from the table. You should use the WHERE clause to filter the records and fetching only the necessary records.
The value of CASE statements is not limited to providing a simple conditional logic in our queries. Experienced data scientists should have more than a surface-level understanding of the CASE statement and its uses. Interviewers are likely to ask you questions about different types of CASE expressions and how to write them.

SQL Prompt retrieval object name in the database, the syntax, and code segments automatically, to provide users with the appropriate code for selection. Set automatic script makes the code easier to read - especially useful if the developer is not familiar with the script. SQL Prompt installation needed to use, can significantly improve the coding efficiency.

Provides support for row-level pessimistic locking usingSELECT ... FOR UPDATE or other, database-specific, locking clauses.expr can be any expression but has to evaluate to a boolean value or to a string and it can't include any fields. Groups together rows from the schema that have the same values in the given fields. Using group_by "groups" the query giving it different semantics in the select expression.

If a query is grouped, only fields that were referenced in the group_by can be used in the select or if the field is given as an argument to an aggregate function. LINQ to SQL offers an alternative model to plan and develop the data-access layer of .NET applications. Through LINQ to SQL, you can realize a brand new data-access layer and use auto-generated types to exchange data with the business and presentation layers. Any query that you express through the LINQ syntax is translated into a T-SQL statement and run. The execution of this statement is transparent to developers, and so is the dynamically generated T-SQL. LINQ to SQL is much more than just a high-level version of T-SQL, but keep in mind that it may not always be able to achieve the same results you can get out of raw T-SQL.

LINQ to SQL queries have their own logic, and the underlying behavior might not be exactly what you expect. LINQ to SQL produces T-SQL statements, but it's a totally different engine—so don't make assumptions about LINQ to SQL behavior before you have verified how it works in practice. LINQ to SQL is a brand-new API for operating on a SQL Server database; it's not just another way of writing T-SQL code.
Let's see now how to perform more advanced query that involve joining and grouping operations on data. LINQ to SQL works by exposing an object-based query language to developers and producing T-SQL statements in response to their input. With LINQ to SQL, you don't explicitly use a connection string, nor do you open or close a connection explicitly. All you do is interact with a central console called the data context. If you look closely, you'll see that this query is not so complicated. The initial SELECT simply selects every column in the users table, and then inner joins it with the duplicated data table from our initial query.




